
TornadoVM: A practical and efficient framework for accelerating managed programming languages on heterogeneous hardware accelerators
TornadoVM is a plugin component to OpenJDK and GraalVM that allows developers of various programming languages (e.g. Java, Python, R, JavaScript and others) to accelerate their applications on heterogeneous devices such as GPUs and FPGAs while improving power efficiency, all without any code modifications.
TornadoVM is a system software that addresses the fundamental problem of achieving higher performance and energy efficiency on current heterogeneous architectures. Unlike traditional approaches, TornadoVM takes a different approach in which programmability and energy efficiency are parts of the core design.
Traditional approaches require developers to manually code parts of their code in low-level programming languages in order to be able to execute their programs on hardware accelerators like GPUs and FPGAs.
This task is very challenging and error-prone since developers of high-level programming languages do not have the skillset or knowledge to write such low-level programs. In addition, since more than one programming language is required, the code base is split into different segments adding overheads in maintainability and debuggability.
In addition, this style of programming hardware accelerators results in monolithic applications in which every time a new device is added to the system, the code must by manually reprogrammed or tuned to perform “optimally” on the new hardware configuration.
TornadoVM solves the challenges mentioned above by eliminating the need to explicitly code the program (or parts of the program) in such low-level languages. Instead, it automatically, dynamically and transparently transforms the user code to optimised code for hardware acceleration.
Tasks such as code generation, memory management, and others are handled transparently by the system. Therefore, developers may keep working on their preferred high-level programming language while at the same time, reaping the benefits of hardware acceleration.
If the code is not suitable for acceleration, the system will fall back into traditional CPU-execution mode. This way, TornadoVM guarantees that there will be no performance degradation compared to the standard way for computing; it can only yield orders of magnitude higher performance if suitable parts for acceleration is found.
In general, TornadoVM is suitable for accelerating data parallel workloads or applications that exhibit pipelined execution. Examples of such applications are deep learning, machine learning, mathematical and physics simulations, computational photography, computer vision, financial applications, and signal processing.
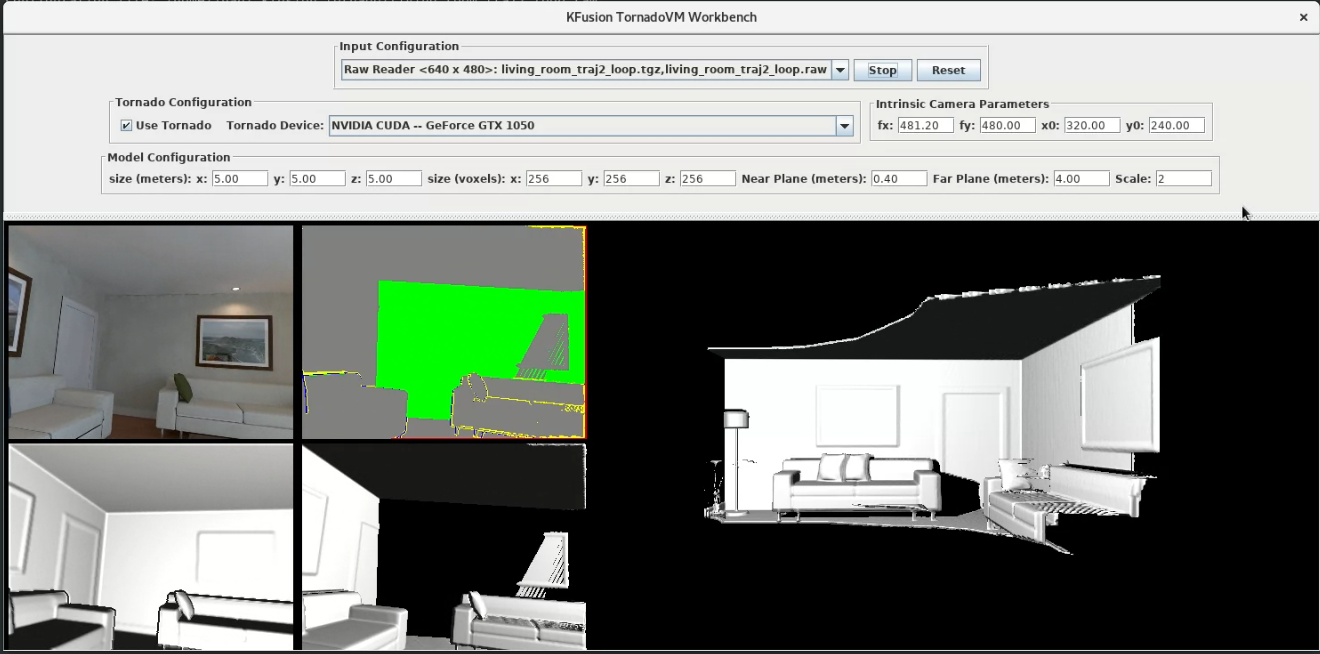
The following figure captures a snapshot of a Java application designed for the acceleration of computer graphics running with TornadoVM on an NVIDIA GPU.
Key Features:
• Enables hardware acceleration of managed programming languages (e.g., Java, JS, Python, R, Scala).
• Applicable to stand-alone desktop, mobile, and cloud applications.
• Increased performance of new and existing software.
• Extensive coverage of hardware devices (Intel/AMD/ARM/NVIDIA/Xilinx CPUs, GPUs, and FPGAs)
• Automatic and transparent code specialisation for each accelerator.
• Live-task migration between devices in a transparent manner.
• Dynamic adaptability to the fastest device to achieve high-performance.
• Integration with Big Data frameworks.
• Easily extensible to new back-ends and new hardware technologies for the acceleration of applications
For more information, please get in touch with the project manager.
